データを見るのって楽しいですよね。データを可視化することも好きですし、予測精度が高い統計モデルを作れたときも嬉しいです。僕ら人間が直感的に把握できない法則のようなものが潜んでいると思うとワクワクします。
今仕事で使っているデータは、データ数が非常に少なく精度があまり出ません。そこでたまには、大量のデータを使って機械学習をしてみたいなぁと思いKaggleのデータを使って趣味として機械学習をしてみることにしました。
目次
今回使ったデータセット
「Predicting a Pulsar Star」というデータセットを使いました。パルサーというのは、非常に規則正しい周期で電波やX線を放射する星のことです。このデータセットは説明変数として計測器の信号データ8種、目的変数としてパルサーか否かの情報が含まれています。(0:パルサー以外、1:パルサー)
今回はデータを統計的に扱いたいというモチベーションなので、パルサーについての詳細は扱いません。詳しく知りたい方はWikipedia「パルサー」をご覧ください。
早速分析していきます
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn
from tensorflow import keras
import tensorflow as tf
from tensorflow.keras import layers
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from tensorflow.keras.callbacks import EarlyStopping
%matplotlib inline
#データの読み込み
master_data = pd.read_csv('pulsar_stars.csv')
data = master_dataまずは必要なモジュールをインポートします。僕の場合、読み込み先のデータはmaster_dataとしてずっと保持しておき、dataのほうをいろいろ整形していきます。
data.head()
とりあえず、最初の5行だけ見てみます。
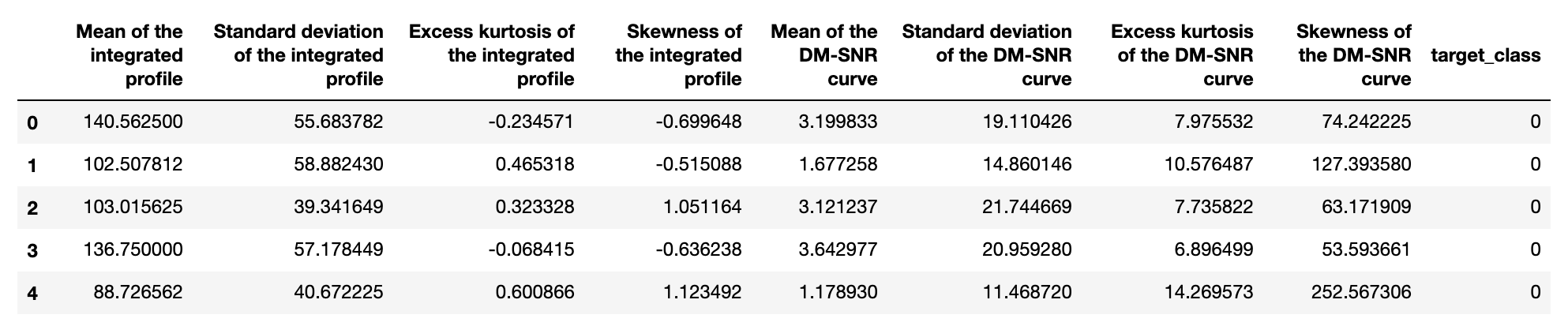
なんとなくそれっぽい数字が入っているのが分かりました。他にも情報を拾ってみます。
data.info()

これはすごい!欠損値Nanはあらかじめ落とされているようです。データ数は17898ですね。これだけあると楽しみです。
data.describe()
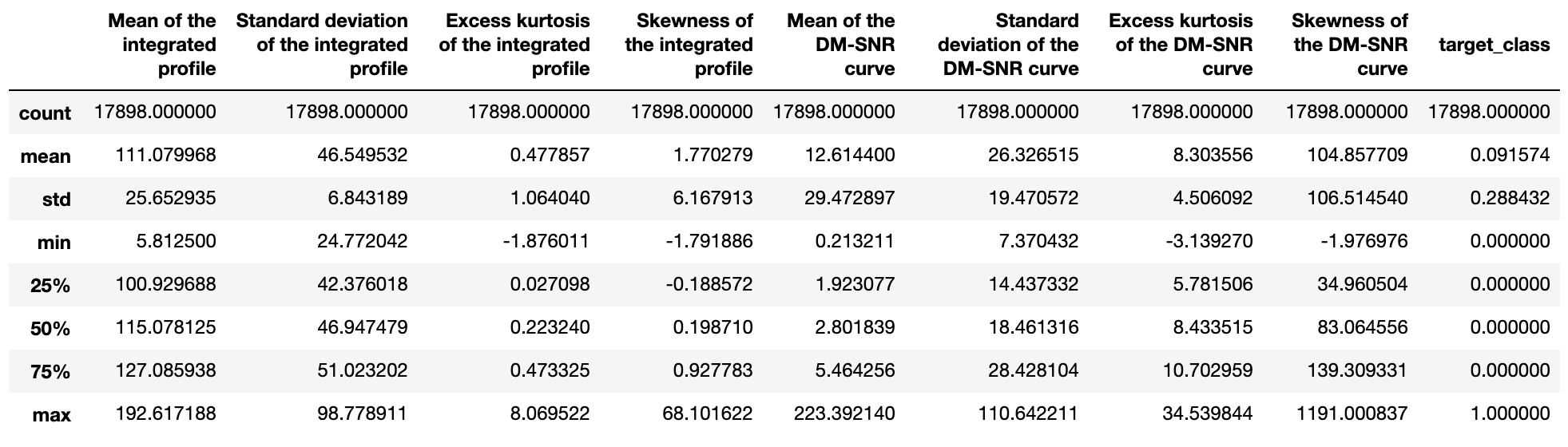
mean(平均)を見ると、変数によってとる値の範囲が結構違いそうです。負の値になるものもあれば、正の値しか取らないものもありますね。一番右のtarget_class(パルサーか否か)は0か1しか取らないので気にしないでください。
#各列名の最初にある半角空白を削除する
column_list = [name.strip() for name in data.columns]
data.columns = column_list
#ヒストグラムに描画
plt.figure(figsize=(17, 35), dpi=200)
i = 1
for col in column_list:
plt.subplot(5, 2, i)
#plt.hist(data[col])
sns.distplot(data[col])
plt.title(col)
i += 1数字だけだとイメージしにくいので、グラフをつくってみます。その前に元データの列名には頭に半角空白” “が入っていて、ややこしいのでそれを取ることにします。
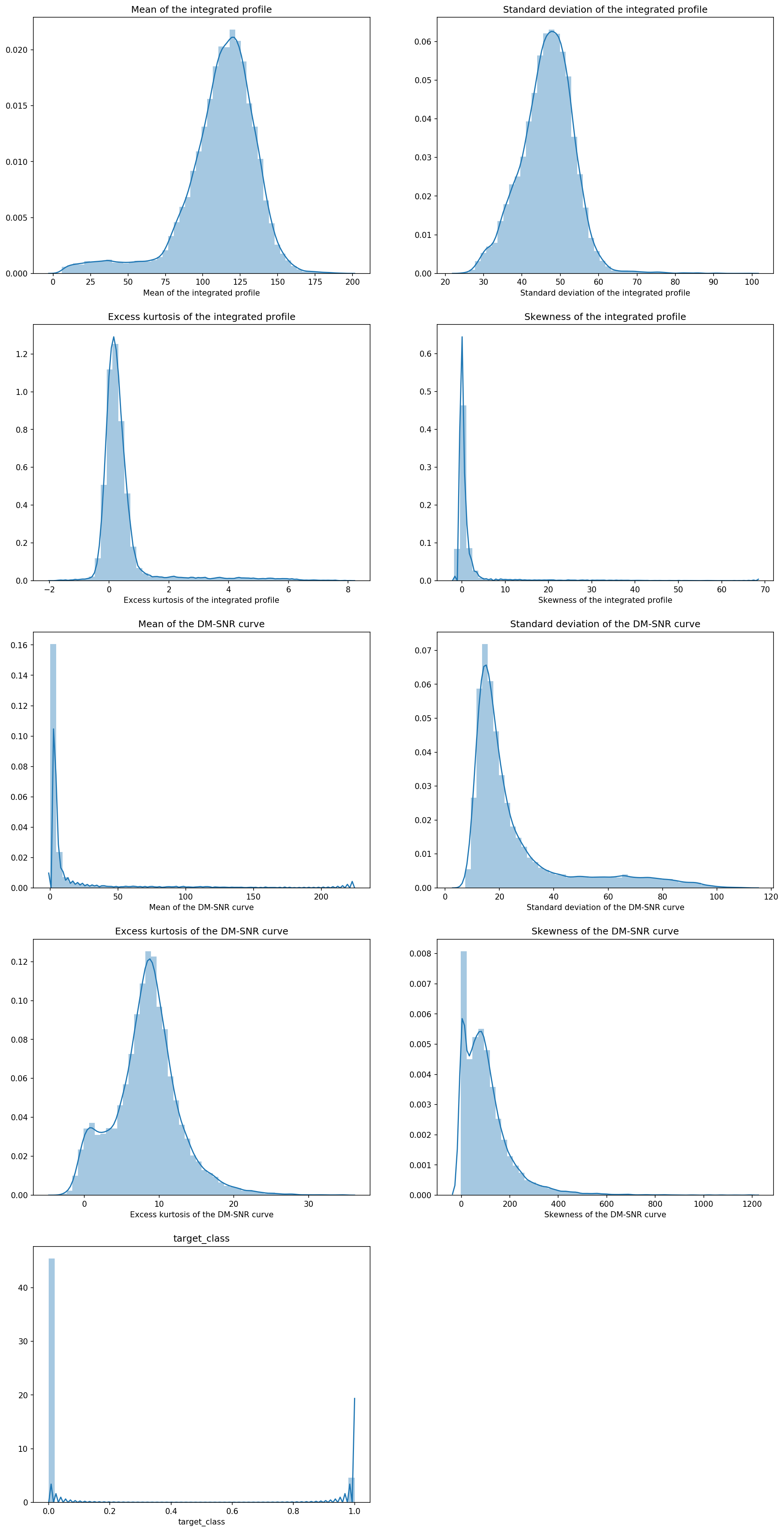
正規分布のようなものや、ポアソン分布のようなものなどありました。明らかに異常と思われるデータもありませんので、どうやらこのまま使えそうです。曲線はカーネル密度推定を行ったものです。
X = data.drop(['target_class'],axis=1)
Y = data['target_class']
#標準化を行う
def norm(x):
mean = np.mean(x)
std = np.std(x)
return (x - mean) / std
X_normed = norm(X)
train_x, test_x, train_y, test_y = sklearn.model_selection.train_test_split(X_normed, Y)説明変数Xと目的変数Yに分けて、Xを正規化します。そして、正規化したX_normとYを使ってトレーニング用とテスト用にデータを分割します。
# エポックが終わるごとにドットを一つ出力することで進捗を表示
class PrintDot(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if epoch % 100 == 0: print('')
print('.', end='')
#DNNのモデル構築
def make_dnn_model(train_x, test_x, train_y, test_y):
log_filepath = 'logs'
tbcb = keras.callbacks.TensorBoard(log_dir=log_filepath)
model = Sequential()
model.add(Dense(20, activation="relu", input_shape=[len(train_x.keys(),)])),
model.add(Dense(20, activation="relu")),
model.add(Dense(2, activation="softmax"))
model.compile(loss='sparse_categorical_crossentropy', optimizer="SGD", metrics=['accuracy'])
EPOCHS = 1000
history = model.fit(train_x, train_y, epochs=EPOCHS, validation_split = 0.2, verbose=0 ,batch_size=32,
callbacks=[EarlyStopping(patience=50), PrintDot()])
return model, historyさっそくKerasを使ってモデルを定義していきます。今回は説明変数が8つしかなかったので、層とニューロン数は抑えめに設定しました。
活性化関数はとりあえずReluを使い、出力層の活性化関数はsoftmaxです。損失関数はsparse categorical entropy,つまり目的変数をone-hotにした上でクロスエントロピーを利用します。出力層の数を2に設定していることを思い出してください。最適化アルゴリズムはとりあえずSGDです。
model,history = make_dnn_model(train_x, test_x, train_y, test_y)
レッツディープラーニング!
#DNNの学習結果をグラフに描画する
def plot_history(history):
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
plt.figure(figsize=(8,3),dpi=150)
plt.xlabel('Epoch()')
plt.ylabel('Accuracy')
plt.plot(hist['epoch'], hist['acc'],
label='Train Error')
plt.plot(hist['epoch'], hist['val_acc'],
label = 'Val Error')
plt.legend()
plt.figure(figsize=(8,3),dpi=150)
plt.xlabel('Epoch()')
plt.ylabel('Loss')
plt.plot(hist['epoch'], hist['loss'],
label='Train Error')
plt.plot(hist['epoch'], hist['val_loss'],
label = 'Val Error')
plt.legend()
plot_history(history)学習が終わりました。今回はエポック50回連続でlossが改善しなかった場合は打ち切るように設定しましたが、念の為に学習曲線を見てみます。
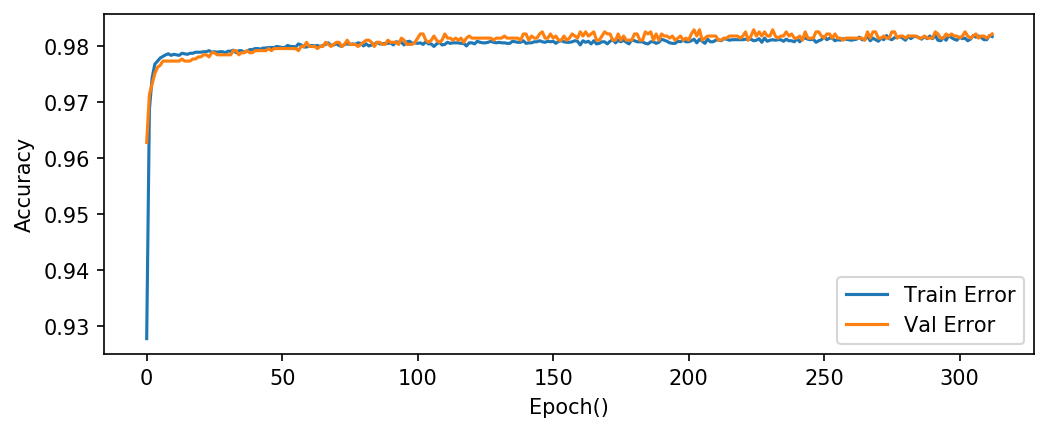
検証データに対する精度は98%を超えています。かなりいい精度です。

クロスエントロピーも0.05にかなり近いところまで来ました。今後の課題として、もう少し精度が上げられそうな気がします。
model.evaluate(test_x, test_y, batch_size=8) #[0.07484402688771653, 0.9781005586592179]
テストデータに対するlossは0.074、正解率は97.8%です。じっくりとハイパーパラメーターを選んだわけではありませんが、かなり高い正解率のモデルをつくることが出来ました!
感想
質も量も十分だったからなのか、簡単に90%以上の精度を出すことが出来ました。Kerasを使うことで簡単にディープラーニングを行うことが出来るというすごい時代になったなとしみじみ思うのでした。